來自特征工程
特征工程,是指用一系列工程化的方式從原始數(shù)據(jù)中篩選出更好的數(shù)據(jù)特征,以提升模型的訓(xùn)練效果。業(yè)內(nèi)有一句廣為流傳的話是:數(shù)據(jù)和特征決定了機器學(xué)習(xí)的上限,而模型和算法是在逼近這個上限而已。由此可見,好的數(shù)據(jù)和特征是模型和算法發(fā)揮更大的作用的前提。特征工程通常包括數(shù)據(jù)預(yù)處理、特征選擇、降維等環(huán)節(jié)。
數(shù)據(jù)預(yù)處理
數(shù)據(jù)預(yù)處理是特征工程中最為重要的一個環(huán)節(jié),良好的數(shù)據(jù)預(yù)處理可以使模型的訓(xùn)練達(dá)到事半功倍的效果。數(shù)據(jù)預(yù)處理旨在通過歸一化、標(biāo)準(zhǔn)化、正則化等方式改進(jìn)不完整、不一致、無法直接使用的數(shù)據(jù)。具體方法有:
歸一化
歸一化是對數(shù)據(jù)集進(jìn)行區(qū)間縮放,縮放到[0,1]的區(qū)間內(nèi),把有單位的數(shù)據(jù)轉(zhuǎn)化為沒有單位的數(shù)據(jù),即統(tǒng)一數(shù)據(jù)的衡量標(biāo)準(zhǔn),消除單位的影響。這樣方便了數(shù)據(jù)的處理,使數(shù)據(jù)處理更加快速、敏捷。Skearn(Scikit learn 也簡稱 sklearn, 是機器學(xué)習(xí)領(lǐng)域當(dāng)中最知名的 python 模塊之一.
)中最常用的歸一化的方法是:MinMaxScaler。此外還有對數(shù)函數(shù)轉(zhuǎn)換(log),反余切轉(zhuǎn)換等。
標(biāo)準(zhǔn)化
標(biāo)準(zhǔn)化是在不改變原數(shù)據(jù)分布的前提下,將數(shù)據(jù)按比例縮放,使之落入一個限定的區(qū)間,使數(shù)據(jù)之間具有可比性。但當(dāng)個體特征太過或明顯不遵從高斯正態(tài)分布時,標(biāo)準(zhǔn)化表現(xiàn)的效果會比較差。標(biāo)準(zhǔn)化的目的是為了方便數(shù)據(jù)的下一步處理,比如:進(jìn)行的數(shù)據(jù)縮放等變換。常用的標(biāo)準(zhǔn)化方法有z-score標(biāo)準(zhǔn)化(是以標(biāo)準(zhǔn)差為單位計算原始分?jǐn)?shù)和母體平均值之間的距離)、StandardScaler標(biāo)準(zhǔn)化(處理的對象是每一列,也就是每一維特征,將特征標(biāo)準(zhǔn)化為單位標(biāo)準(zhǔn)差或是0均值)等。
離散化
離散化是把連續(xù)型的數(shù)值型特征分段,每一段內(nèi)的數(shù)據(jù)都可以當(dāng)做成一個新的特征。具體又可分為等步長方式離散化和等頻率的方式離散化,等步長的方式比較簡單,等頻率的方式更加精準(zhǔn),會跟數(shù)據(jù)分布有很大的關(guān)系。 代碼層面,可以用pandas中的cut方法進(jìn)行切分。總之,離散化的特征能夠提高模型的運行速度以及準(zhǔn)確率。
二值化
特征的二值化處理是將數(shù)值型數(shù)據(jù)輸出為布爾類型。其核心在于設(shè)定一個閾值,當(dāng)樣本書籍大于該閾值時,輸出為1,小于等于該閾值時輸出為0。我們通常使用preproccessing庫的Binarizer類對數(shù)據(jù)進(jìn)行二值化處理。
啞編碼
我們針對類別型的特征,通常采用啞編碼(One_Hot Encodin)的方式。所謂的啞編碼,直觀的講就是用N個維度來對N個類別進(jìn)行編碼,并且對于每個類別,只有一個維度有效,記作數(shù)字1 ;其它維度均記作數(shù)字0。但有時使用啞編碼的方式,可能會造成維度的災(zāi)難,所以通常我們在做啞編碼之前,會先對特征進(jìn)行Hash處理,把每個維度的特征編碼成詞向量。
以上為大家介紹了幾種較為常見、通用的數(shù)據(jù)預(yù)處理方式,但只是浩大特征工程中的冰山一角。往往很多特征工程的方法需要我們在項目中不斷去總結(jié)積累比如:針對缺失值的處理,在不同的數(shù)據(jù)集中,用均值填充、中位數(shù)填充、前后值填充的效果是不一樣的;對于類別型的變量,有時我們不需要對全部的數(shù)據(jù)都進(jìn)行啞編碼處理;對于時間型的變量有時我們有時會把它當(dāng)作是離散值,有時會當(dāng)成連續(xù)值處理等。所以很多情況下,我們要根據(jù)實際問題,進(jìn)行不同的數(shù)據(jù)預(yù)處理。
特征選擇
不同的特征對模型的影響程度不同,我們要自動地選擇出對問題重要的一些特征,移除與問題相關(guān)性不是很大的特征,這個過程就叫做特征選擇。特征的選擇在特征工程中十分重要,往往可以直接決定最后模型訓(xùn)練效果的好壞。常用的特征選擇方法有:過濾式(filter)、包裹式(wrapper)、嵌入式(embedding)。
過濾式
過濾式特征選擇是通過評估每個特征和結(jié)果的相關(guān)性,來對特征進(jìn)行篩選,留下相關(guān)性最強的幾個特征。核心思想是:先對數(shù)據(jù)集進(jìn)行特征選擇,然后再進(jìn)行模型的訓(xùn)練。過濾式特征選擇的優(yōu)點是思路簡單,往往通過Pearson相關(guān)系數(shù)法、方差選擇法、互信息法等方法計算相關(guān)性,然后保留相關(guān)性最強的N個特征,就可以交給模型訓(xùn)練;缺點是沒有考慮到特征與特征之間的相關(guān)性,從而導(dǎo)致模型最后的訓(xùn)練效果沒那么好。
包裹式
包裹式特征選擇是把最終要使用的機器學(xué)習(xí)模型、評測性能的指標(biāo)作為特征選擇的重要依據(jù),每次去選擇若干特征,或是排除若干特征。通常包裹式特征選擇要比過濾式的效果更好,但由于訓(xùn)練過程時間久,系統(tǒng)的開銷也更大。最典型的包裹型算法為遞歸特征刪除算法,其原理是使用一個基模型(如:隨機森林、邏輯回歸等)進(jìn)行多輪訓(xùn)練,每輪訓(xùn)練結(jié)束后,消除若干權(quán)值系數(shù)較低的特征,再基于新的特征集進(jìn)行新的一輪訓(xùn)練。
嵌入式
嵌入式特征選擇法是根據(jù)機器學(xué)習(xí)的算法、模型來分析特征的重要性,從而選擇最重要的N個特征。與包裹式特征選擇法最大的不同是,嵌入式方法是將特征選擇過程與模型的訓(xùn)練過程結(jié)合為一體,這樣就可以快速地找到最佳的特征集合,更加高效、快捷。常用的嵌入式特征選擇方法有基于正則化項(如:L1正則化)的特征選擇法和基于樹模型的特征選擇法(如:GBDT)。
降維
如果拿特征選擇后的數(shù)據(jù)直接進(jìn)行模型的訓(xùn)練,由于數(shù)據(jù)的特征矩陣維度大,可能會存在數(shù)據(jù)難以理解、計算量增大、訓(xùn)練時間過長等問題,因此我們要對數(shù)據(jù)進(jìn)行降維。降維是指把原始高維空間的特征投影到低維度的空間,進(jìn)行特征的重組,以減少數(shù)據(jù)的維度。降維與特征最大的不同在于,特征選擇是進(jìn)行特征的剔除、刪減,而降維是做特征的重組構(gòu)成新的特征,原始特征全部“消失”了,性質(zhì)發(fā)生了根本的變化。常見的降維方法有:主成分分析法(PCA)和線性判別分析法(LDA)。
主成分分析法
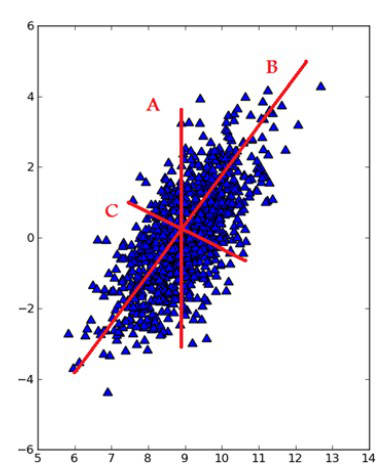
主成分分析法(PCA)是最常見的一種線性降維方法,其要盡可能在減少信息損失的前提下,將高維空間的數(shù)據(jù)映射到低維空間中表示,同時在低維空間中要最大程度上的保留原數(shù)據(jù)的特點。主成分分析法本質(zhì)上是一種無監(jiān)督的方法,不用考慮數(shù)據(jù)的類標(biāo),它的基本步驟大致如下:
- 數(shù)據(jù)中心化(每個特征維度減去相應(yīng)的均值)
- 計算協(xié)方差矩陣以及它的特征值和特征向量
- 將特征值從大到小排序并保留最上邊的N個特征
- 將高維數(shù)據(jù)轉(zhuǎn)換到上述N個特征向量構(gòu)成的新的空間中
此外,在把特征映射到低維空間時要注意,每次要保證投影維度上的數(shù)據(jù)差異性最大(也就是說投影維度的方差最大)。我們可以通過圖1-5來理解這一過程:
線性判別分析法
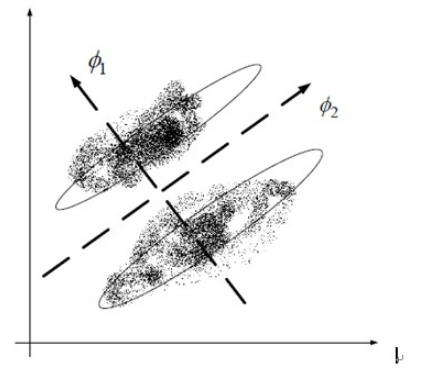
線性判別分析法(LDA)也是一種比較常見的線性降維方法,但不同于PCA的是,它是一種有監(jiān)督的算法,也就是說它數(shù)據(jù)集的每個樣本會有一個輸出類標(biāo)。線性判別算法的核心思想是,在把數(shù)據(jù)投影到低維空間后,希望同一種類別數(shù)據(jù)的投影點盡可能的接近,而不同類別數(shù)據(jù)的類別中心之間的距離盡可能的遠(yuǎn)。也就是說LDA是想讓降維后的數(shù)據(jù)點盡可能地被區(qū)分開。其示例圖如下所示:
以上為大家總結(jié)了常用的一些特征工程方法,我們可以使用sklearn完成幾乎所有特征處理的工作,具體參考:
http://scikit-learn.org/stable/modules/preprocessing.html#preprocessing。
