剖析Spark工作的運行
我們來看下當我們運行一個Spark工作時,會發生什么。在最高級別上,有兩個獨立的實體:驅動(driver)和執行器(executors)。驅動持有(hosts)應用(SparkContext),為工作調度任務。執行器獨立于應用,在應用的持續時間內運行,執行應用的任務。通常情況下,驅動作為客戶端運行,不受集群管理器的管理,而執行器運行在集群中的多臺機器上,但并非總是如此。在本節的其余部分,我們假定應用的執行器已經在運行。
工作的提交
圖19-1說明了Spark是怎樣運行一個工作的。當在一個RDD上執行一個行動時(比如count()),會自動提交一個Spark工作。內部來看,這會導致SparkContext的runJob()方法被調用(圖19-1步驟1),該方法將調用傳遞給調度器,調度器作為驅動的一部分運行(步驟2)。調度器由兩部分組成:DAG調度器和任務調度器。DAG調度器會把工作拆解為多個階段組成的DAG。任務調度器的責任是把每個階段的任務提交到集群。
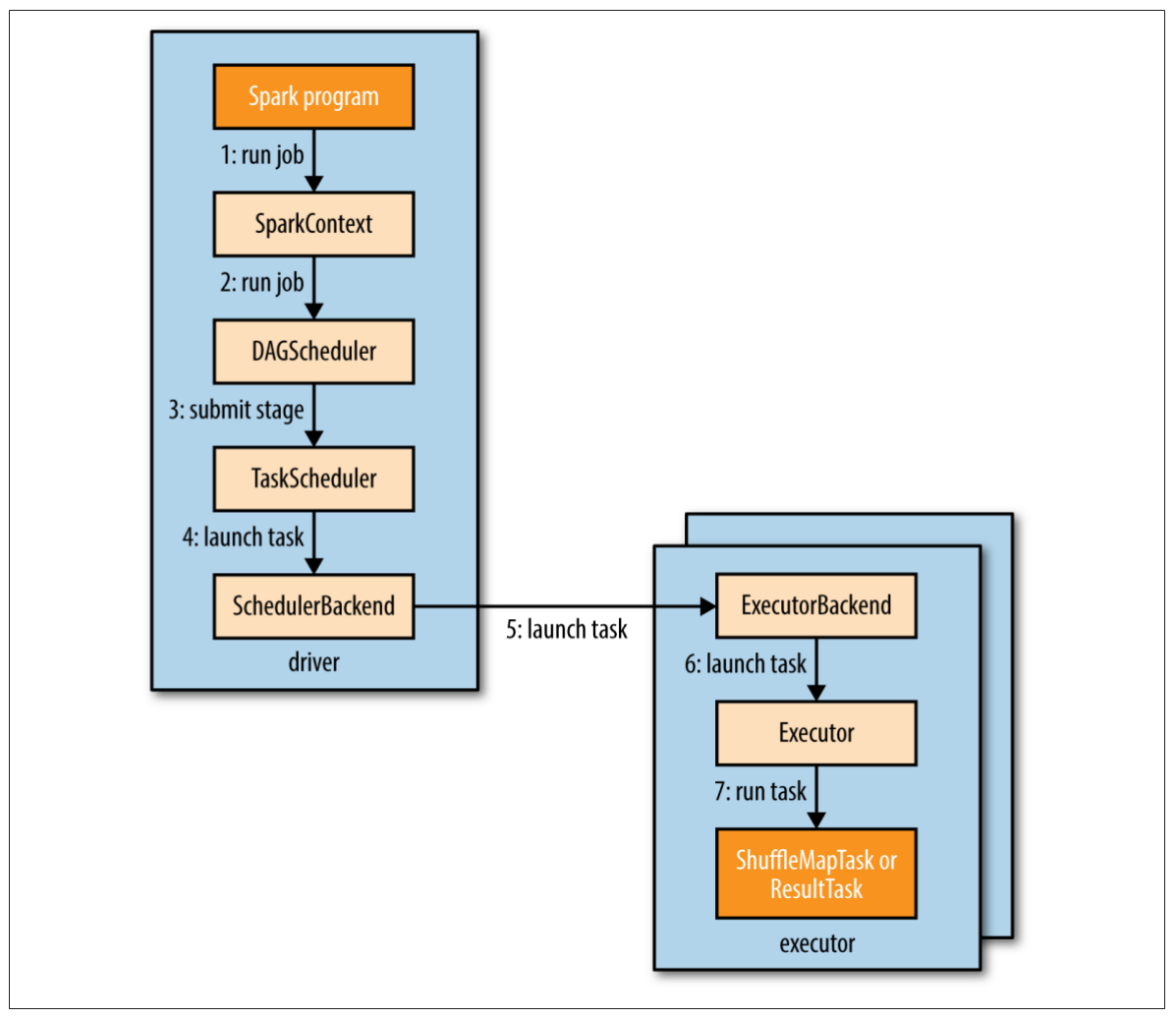
圖19-1. Spark怎樣運行一個工作
接下來,我們來看看DAG調度器是怎樣構建一個DAG的。
DAG的構建
為了理解怎樣把一個工作拆分為階段,我們需要看看階段中運行的任務的類型。有兩種任務類型:混洗map任務 shuffle map tasks 和結果任務 result tasks。任務類型的名字指示出Spark如何處理任務的輸出:
混洗map任務
正如名字所暗示的,混洗map任務就像MapReduce中的map側混洗。每個混洗map任務在一個RDD分區上(基于分區函數)執行計算,把輸出寫到一組新的分區,供后續的階段獲取,后續階段可能由混洗map任務或者結果任務組成。混洗map任務運行在除最終階段以外的所有階段中。
結果任務
結果任務運行于最終階段,把結果返回給用戶程序(比如count()的結果)。每個結果任務在它的RDD分區上執行計算,然后把結果返回給驅動,驅動再把每個分區的結果組合成最終結果(可能是Unit,在saveAsTextFile()情況下)。
如果不需要混洗,僅有一個由結果任務組成的單獨的階段,這是最簡單的Spark工作,就像MapReduce中僅有map任務的工作一樣。
更復雜的工作會包含grouping操作,并且須要一個或多個混洗階段。例如,存儲在inputPath的文本文件(每行一個單詞),下面的工作會計算出單詞數量的直方圖:
val hist: Map[Int, Long] = sc.textFile(inputPath)
.map(word => (word.toLowerCase(), 1))
.reduceByKey((a, b) => a + b)
.map(_.swap)
.countByKey()
前面兩個轉換操作,map()和reduceByKey(),執行單詞計數。第三個map()轉換操作,會把每個鍵值對的key和value交換,輸出(count, word)對。最后一個是行動操作,countByKey(),返回每個count的word數量(單詞數量的頻率分布)。
Spark的DAG調度器把這個工作切分為兩個階段,因為reduceByKey()操作強制了一個混洗階段。結果DAG如圖19-2所示。
注意countByKey()是在驅動程序的本地執行最終的聚合操作,而不是第二個混洗階段。這里不同于示例18-3中的Crunch程序,該程序使用了第二個MapReduce工作來做計數。
圖19-2. 計算詞數直方圖的Spark工作中的階段和RDD
一般來說,每個階段內的RDD也會整理到DAG中。上圖顯示了RDD的類型和創建該RDD的操作。例如,RDD[String]是由textFile()創建的。為了簡化圖示,這里省略了Spark內部生成的一些中間RDD。比如,textFile()返回的RDD實際上是MapRDD[String],其父是HadoopRDD[LongWritable, Text]。
注意到轉換操作reduceByKey()跨越了兩個階段,這是因為它的實現是一個混洗過程,該reduce函數在map側作為combiner運行,在reduce側作為reducer運行,正如MapReduce一樣。還是與MapReduce相同,Spark的混洗實現會把輸出寫到本地磁盤的分區文件(即使是內存RDD也一樣),這些文件被下一階段的RDD讀取。
通過配置,混洗的性能還有調優的余地。還要注意Spark使用自定義的混洗實現,與MapReduce的混洗實現沒有任何的共享代碼。
如果一個RDD在同一應用(SparkContext)中的前一個工作中持久化過,DAG調度器不會再創建重算這個RDD及其父RDD的階段。
DAG調度器的責任是把階段拆分為任務,提交給任務調度器。在這個例子中,第一個階段,輸入文件的每個分區對應運行一個混洗map任務。reduceByKey()操作的并行級別可以明確指定(傳入第二個參數),如果不指定的話,將由父RDD確定,本例中是輸入數據的分區數量。
DAG調度器為每個任務指定位置首選項,使得任務調度器可以利用數據本地化的優勢。例如,如果一個任務處理的是存儲在HDFS上的RDD分區,它的位置首選項是該分區的塊(block)所在的數據節點(datanode),被稱為節點本地 node local。如果一個任務處理的是緩存在內存中的RDD分區,它的位置首選項是存儲該分區的執行器(executor),被稱為進程本地 process local。
回到圖19-1,一旦DAG調度器創建了完整的階段DAG,它就會把每個階段的任務集提交給任務調度器(步驟3)。父階段成功完成之后,子階段才會提交。
任務的調度
當任務調度器接收到一坨任務時,它會查找執行器列表,在考慮位置首選項的基礎上,建立任務到執行器的映射關系。接著,任務調度器把任務分配給那些有空閑核心的執行器(如果同一應用中的其他工作正在運行的話,這坨任務可能分配不完),隨著執行器中任務的運行完成,調度器會繼續分配更多的任務,直到這一坨任務全部完成。每個任務分配到的核心數量,可以通過屬性spark.task.cpus來設置,默認是1。
對于某個特定的執行器,調度器首先為它分配進程本地(process-local)任務,然后是節點本地(node-local)任務,然后是機架本地(rack-local)任務,最后是任意的非本地(nonlocal)任務,或者是“推測(speculative)任務”,如果沒有其他候選者的話。
被分配的任務通過調度器后端(scheduler backend)啟動(圖19-1步驟4),它會發送一個遠程“啟動任務消息”(步驟5)給執行器后端(executor backend),告訴執行器要運行任務了(步驟6)。
Spark的遠程調用,使用的不是Hadoop RPC,而是Akka,一個基于actor模型的平臺,用于構建高度可伸縮的、事件驅動的分布式應用。
當一個任務完成或者失敗的時候,執行器會發送“狀態更新消息”給驅動。如果任務失敗,任務調度器會在另一個執行器上重新提交該任務。如果啟用了“推測任務”,并且有運行比較慢的任務,任務調度器還會啟動“推測任務”。推測任務默認是未啟用的。
任務的執行
執行器運行一個任務的過程如下(步驟7)。首先,它要確認該任務的JAR包和依賴文件都是最新的。前面的任務使用過的依賴文件,會被執行器保持在本地緩存中,只在這些文件變化的時候,執行器才會去下載它們。第二步,執行器反序列化任務的代碼(包括用戶定義的函數),這些代碼是作為“啟動任務消息”的一部分發送過來的序列化字節。第三步,執行任務代碼。注意,任務和執行器運行在同一個JVM中,因此不存在任務啟動的進程開銷(Mesos的細粒度模式是個例外,它的每個任務都是一個獨立的進程)。
任務會把結果返回給驅動。結果序列化之后發送給執行器后端,然后作為“狀態更新消息”返回給驅動。一個混洗map任務返回一些信息,使下一個階段可以獲取它輸出的分區。一個結果任務返回它所運行的分區的結果值,驅動再把這些結果值組裝成最終結果,返回給用戶程序。
執行器和集群管理器
我們已經看過Spark是如何依賴于執行器來執行Spark工作中的任務的,但是我們掩蓋了執行器實際上是怎樣啟動的。管理執行器的生命周期,是集群管理器的責任。Spark提供了多種具有不同特征的集群管理器:
本地
在本地模式下,只有一個執行器,和驅動運行在同一個JVM里。這種模式對于測試和運行小的工作非常有幫助。這種模式的master URL是local(一個線程),local[n](n個線程),或者local(*)(每個核心一個線程)。
獨立
獨立的集群管理器是一個簡單的分布式實現。它運行一個master和一個或多個worker。當一個Spark應用啟動時,master會代表這個應用,指示worker進行執行器進程的創建。這種模式的master URL是spark://host:port。
Mesos
Apache Mesos是一個通用的集群資源管理器,根據一個組織策略,它允許不同的應用之間進行細粒度的資源共享。默認情況下(細粒度模式),每一個Spark任務,就是一個Mesos任務。這樣可以高效利用集群資源,但是付出的代價是額外的進程啟動的開銷。在粗粒度模式下,執行器在進程內運行任務,因此在Spark應用的持續時間內,集群資源由執行器進程所持有。這種模式的master URL是mesos://host:port。
YARN
YARN是Hadoop使用的資源管理器。一個運行中的Spark應用,對應一個YARN的應用實例。一個執行器在它自身的YARN容器中運行。這種模式的master URL是yarn-client或者yarn-cluster。
Mesos和YARN集群管理器,優于獨立模式,因為它們會考慮集群中運行的其他應用的資源需求(比如MapReduce工作),并為這些應用強制執行一個調度策略。獨立模式對集群資源進行靜態分配,因此不能適應其他應用隨著時間變化的需求。并且,YARN是唯一一個和Hadoop的Kerberos安全機制集成的集群管理器。
Spark on YARN
在YARN上運行Spark,可以和其他的Hadoop組件緊密集成,而且如果你已經有了一個Hadoop集群,這是使用Spark的最方便的方式。Spark提供了兩種部署模式:YARN client模式,驅動在client端運行;YARN cluster模式,驅動運行在集群上的YARN application master里。
對于具有交互組件的程序,比如spark-shell或者pyspark,YARN client模式是必須的。當你構建一個Spark程序時,client模式也會非常有幫助,因為任何的調試輸出都是立即可見的。
另一方面,YARN cluster模式適用于生產系統(production job),因為整個應用運行在集群上,這樣能更容易的保留日志文件(包括驅動程序的日志)以備后查。另外,如果application master失敗了,YARN會重試這個應用。
YARN client模式
在YARN client模式中,與YARN的交互開始于驅動程序創建一個新的SparkContext實例的時候(圖19-3步驟1)。SparkContext把一個YARN應用提交給YARN資源管理器(步驟2),YARN資源管理器會在集群中某個節點管理器上啟動一個YARN容器,然后在容器中運行一個Spark ExecutorLauncher應用(步驟3)。這個ExecutorLauncher的工作是通過向資源管理器請求資源(步驟4),在YARN容器中啟動執行器。當容器被分配過來以后,啟動ExecutorBackend進程(步驟5)。
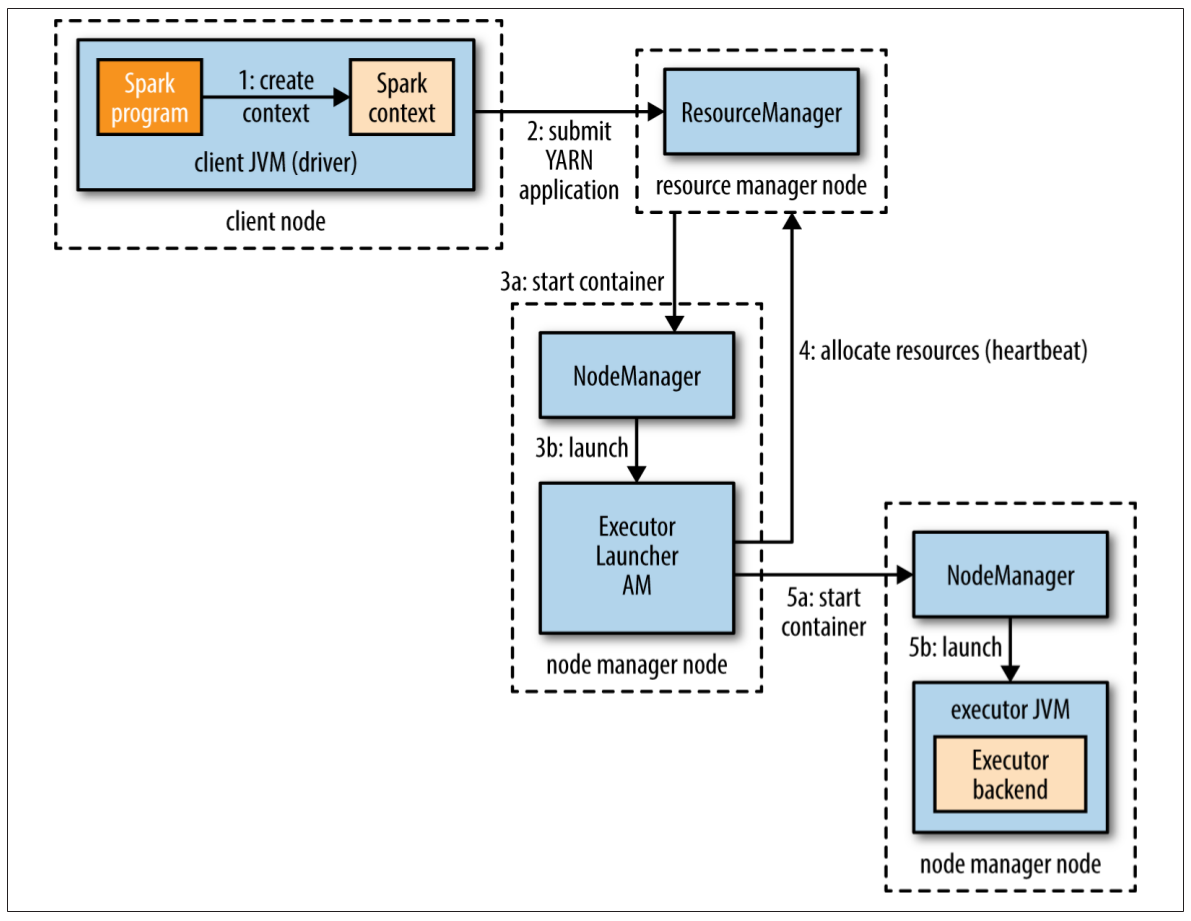
圖19-3. 在YARN client模式下,Spark執行器的啟動過程
執行器啟動以后,會回連到SparkContext并注冊自己。這樣SparkContext中就有了關于可用執行器的數量及其位置的信息。在分配任務時可基于這些位置信息進行決策。
在spark-shell,spark-submit和pyspark中,可以設置要啟動的執行器的數量(如果不設置,默認是2),還有每個執行器使用的核心數量(默認是1)以及內存大小(默認是1024MB)。下面這個例子在YARN上運行spark-shell,配有4個執行器,每個執行器使用1個核心和2G內存:
% spark-shell --master yarn-client \
--num-executors 4 \
--executor-cores 1 \
--executor-memory 2g
YARN資源管理器的地址,沒有在master URL中指定(不同于獨立模式或Mesos集群管理器),而是從Hadoop的配置中獲取(Hadoop的配置位于環境變量HADOOP_CONF_DIR指定的目錄下)。
YARN cluster模式
在YARN cluster模式中,用戶的驅動程序運行在YARN的application master進程中。命令spark-submit的master URL是yarn-cluster:
% spark-submit --master yarn-cluster ...
其他的參數,比如num-executors以及應用的JAR文件(或者Python文件),與YARN client模式相同(使用spark-submit --help查看詳細用法)。
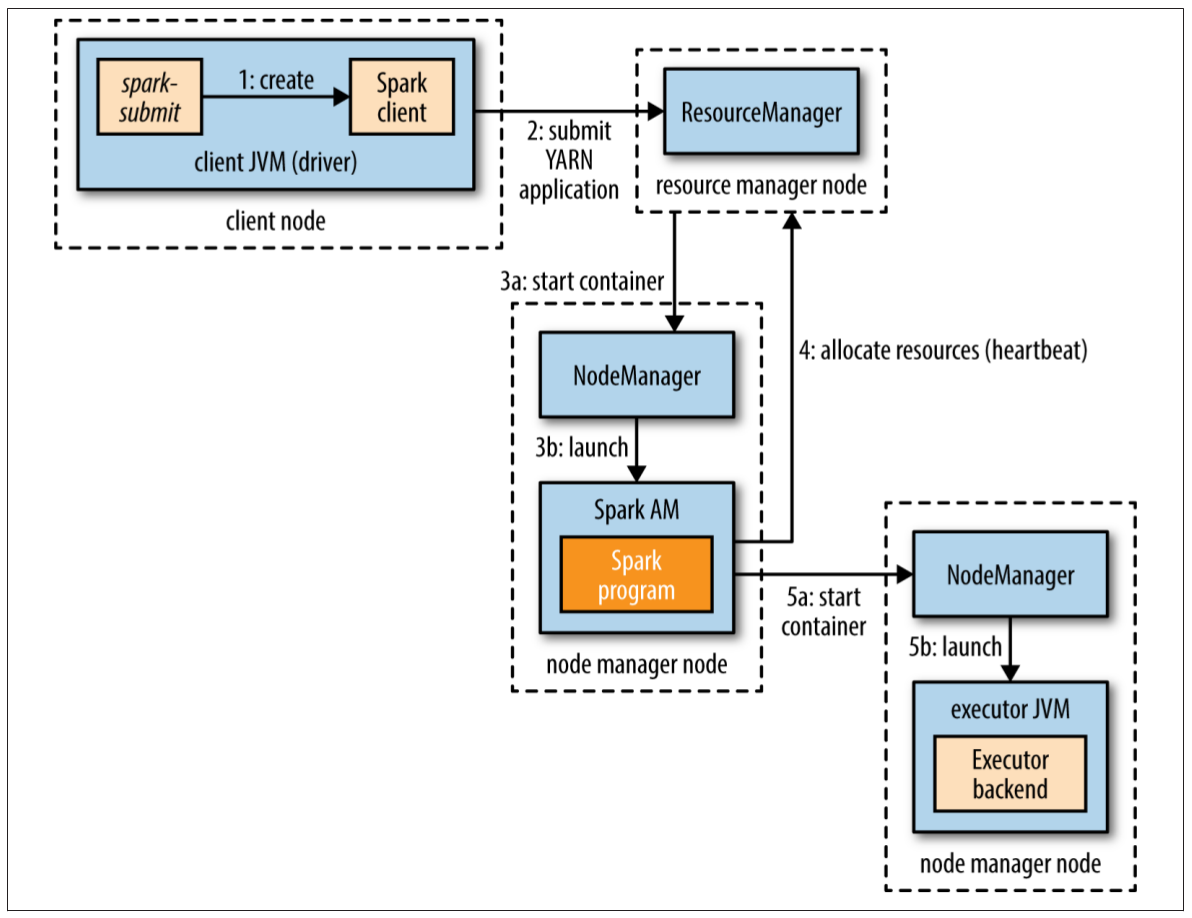
圖19-4. 在YARN cluster模式下,Spark執行器的啟動過程
spark-submit客戶端將會啟動YARN應用(圖19-4步驟1),但它不運行任何的用戶代碼。余下的流程與client模式相同,唯一的不同是,在為執行器分配資源之前(步驟4),驅動程序是由application master啟動的(步驟3b)。
在這兩種YARN模式中,執行器啟動之前沒有任何的數據本地化信息可以使用,因此這些執行器很可能不在那些持有工作對應文件的數據節點上。對于交互式會話,這是可以接受的,因為在會話開始之前可能不知道哪些數據集會被訪問。但是對于生產系統(production job),這就不能接受了。因此Spark提供了一種給出位置線索的方式,以使運行YARN集群模式時的數據本地化程度得到提高。
SparkContext的構造函數可以接收第二個參數,用于指定偏愛的位置。此位置根據輸入格式以及路徑,使用InputFormatInfo幫助類計算而來。例如,對于文本文件,我們使用TextInputFormat:
val preferredLocations = InputFormatInfo.computePreferredLocations(
Seq(new InputFormatInfo(new Configuration(), classOf[TextInputFormat],
inputPath)))
val sc = new SparkContext(conf, preferredLocations)
“偏愛位置”被application master用來向資源管理器請求分配資源(步驟4)。本文寫作時,Spark的最新版本是1.2.0,關于偏愛位置的API還不穩定,后續版本中可能會改變。
延伸閱讀
本章僅僅覆蓋了Spark的基礎知識。更多細節請參閱《Learning Spark》。Apache Spark網站上也有關于Spark最新發行版的最新文檔。
花了一個星期,在寶貝女兒(2歲)持續不斷的騷擾下,終于把這件事情完成了。
