前言
本文是對 Mongo 官方文檔粗略的總結,并沒有涉及到很深的細節(細節還是直接看官方文檔吧)。我認為 Mongo 有重要的就 3 點:
- 存儲引擎原理,如何保證斷電后恢復數據?Mongo 的 data 在文件系統中,是如何組織和保存的?
- Replication
- Sharding
思維導圖
目錄
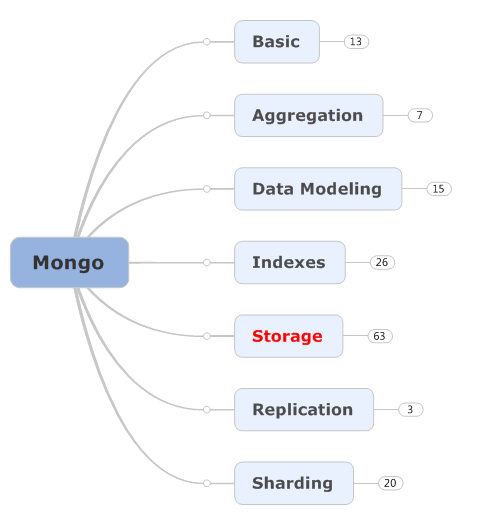
Basic

Aggregation & Data Modeling

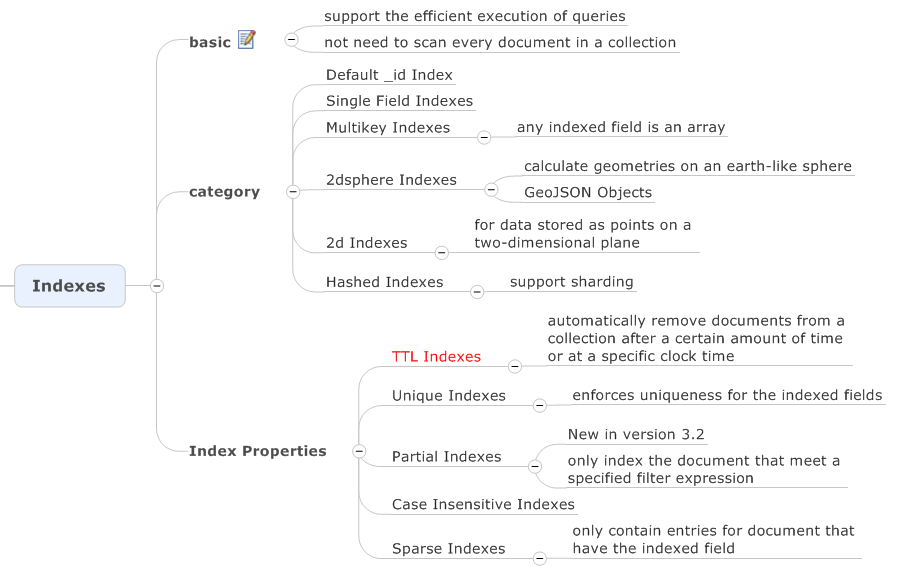
Indexes
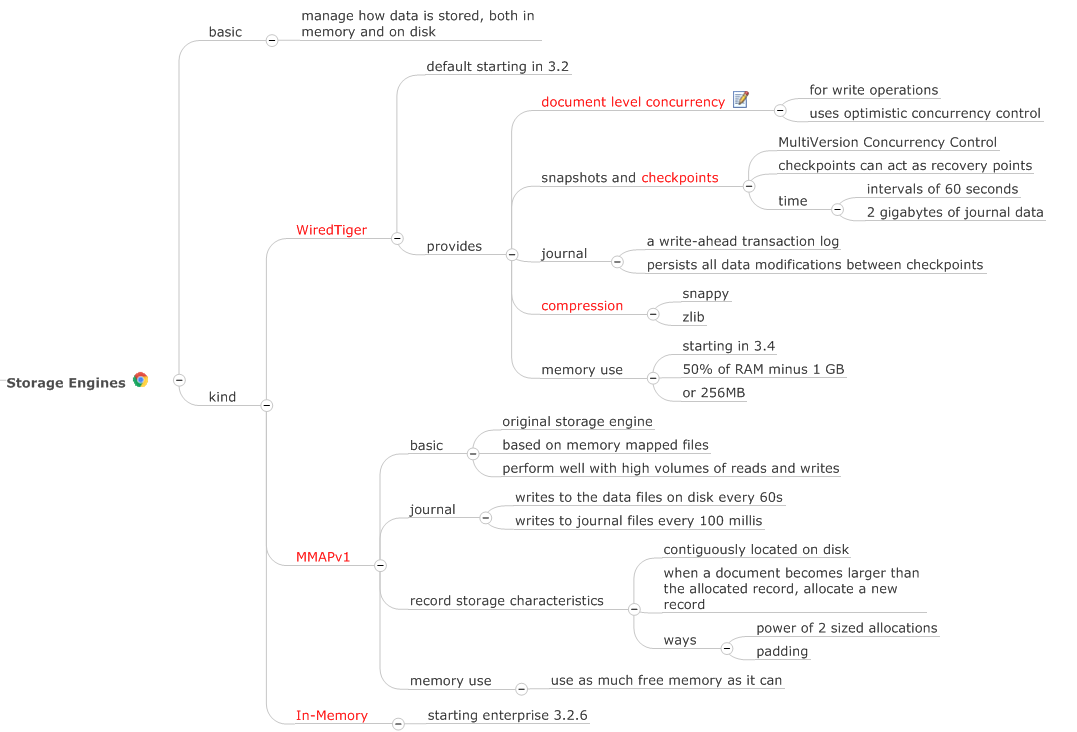
Storage
Replication & Sharding

思考
Document 在內部是如何存儲的?
每個 Document 被保存在一個 Record 中。Record 相當于 MongoDB 內部分配的一塊空間,除了保存 Document 的內容可能還會預留一些填充的額外空間。對于寫入后的 Document 如果還會更新,可能導致 Document 長度增加,就可以利用上額外的填充空間來。若業務對于寫入后的 Document 不會再更新或刪除(像監控日志、流水記錄等),可以指定無填充的 Record 分配策略,更節省空間。
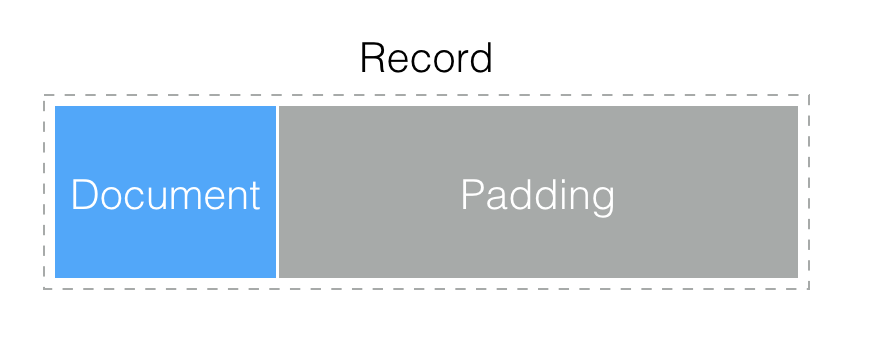
單個 Document 的容量是否有限制?
16MB。Document 這種 JSON 形態天生會帶來數據存儲冗余,主要是 field 屬性每個 Document 都會保存一遍。目前 3.2 版本的 MongoDB 已經將新的 WiredTiger 作為默認存儲引擎,它提供了壓縮功能,有兩種壓縮形式:
-
Snappy默認壓縮算法,在壓縮率和 CPU 開銷之間取得平衡。 -
Zlib更高的壓縮率,但也帶來更高的 CPU 開銷。
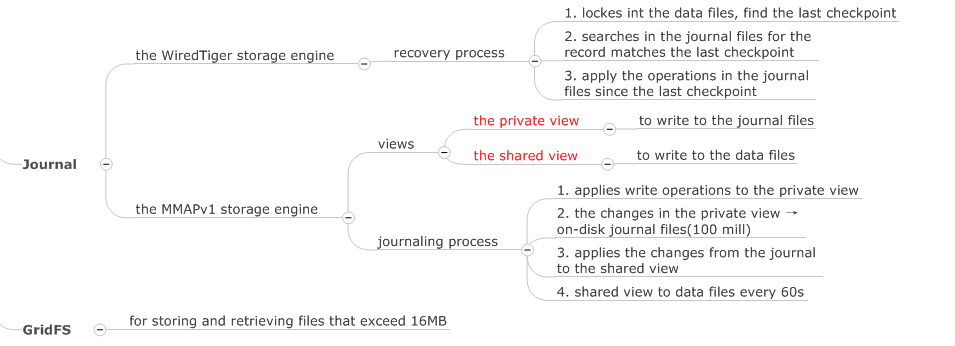
而每個 Document 依然有最大容量限制,不能無限增長下去,這個限制目前是 16MB。那么我要存大于 16MB 的文件怎么辦,MongoDB 提供了 GridFS 來存儲超過 16MB 大小的文件。如下圖所示,一個大文件被拆分成小的 File Chunk,每個 Chunk 大小 255KB,并存放在一個 Document 中。GridFS 使用了 2 個 Collection 來分別存放文件 Chunk 和文件元數據。
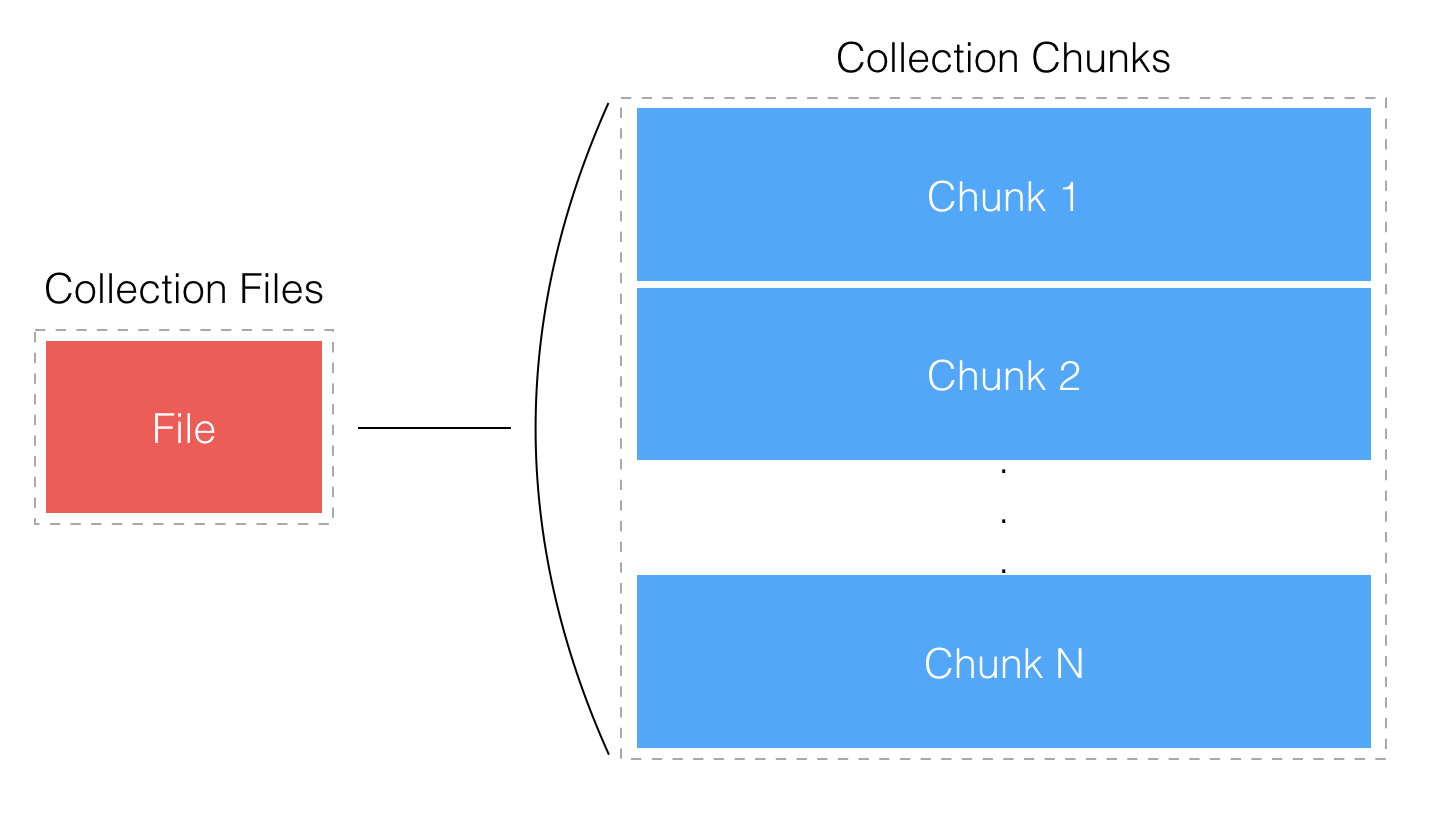
遇到真正的「大數據」(單機存儲容量不夠)怎么辦?
分片化:利用更多的機器來提供更大的容量,分片集群采用代理模式:
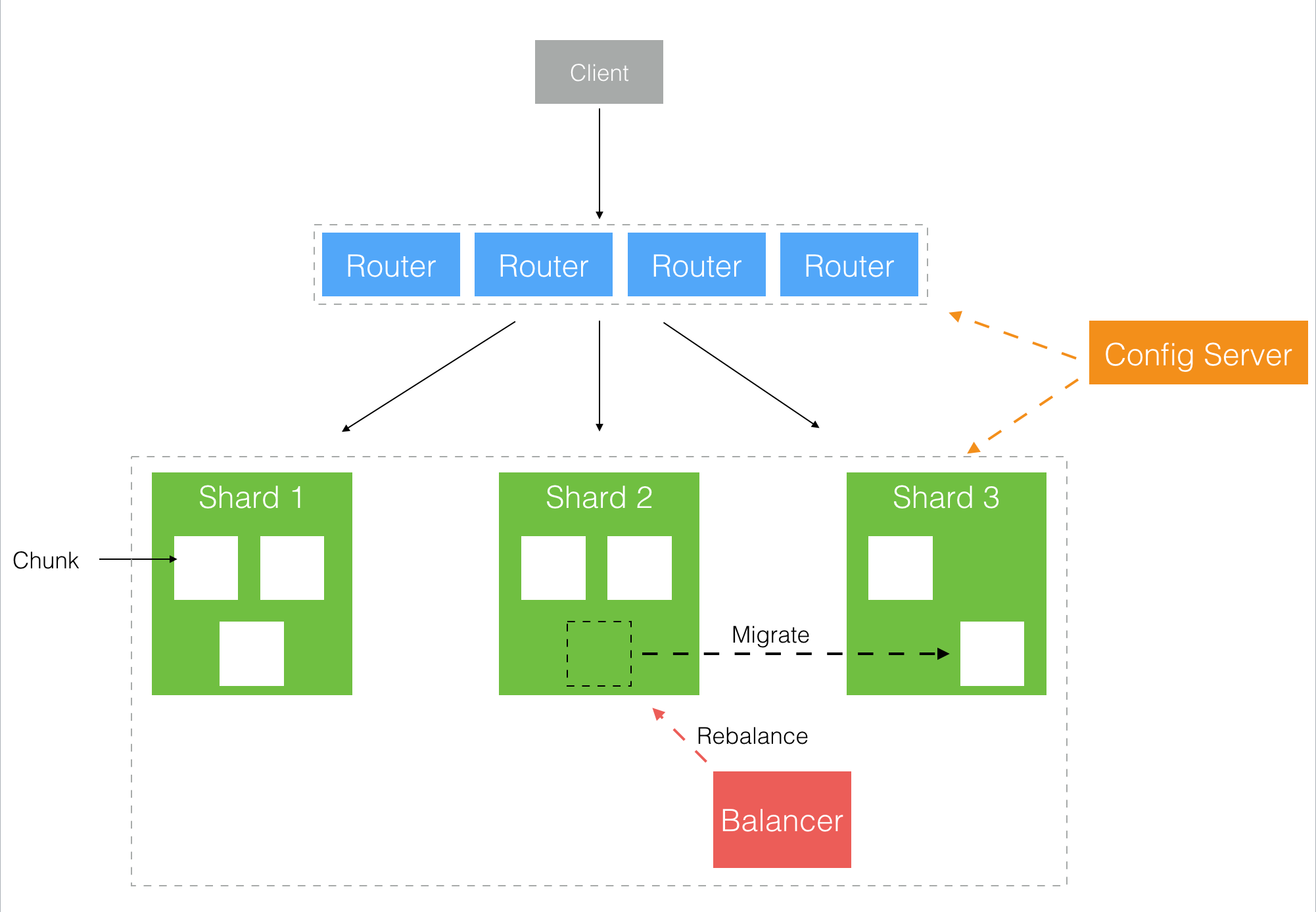
而每個分片上的數據又以 Chunk 的形式組織(類似于 Redis Cluster 的 Slot 概念),以便于集群內部的數據遷移和再平衡。比較容易混淆的是這里的 Chunk 不是前面 GridFS 里提到的 Chunk,它們的關系大概如下圖:

Mongo 的數據安全嗎?在保證效率的同時,在服務器突然宕機的情況下,是否能夠保存數據?
安全和效率其實是相互制約的,越安全則效率越低,越高效則越不安全。MongoDB 的設計場景考慮的是應對大量的數據寫入和查詢,而數據的重要性相對沒那么高。所以 MongoDB 的默認設置在安全和效率之間,更偏向效率。
Write To Buffer Without ACK
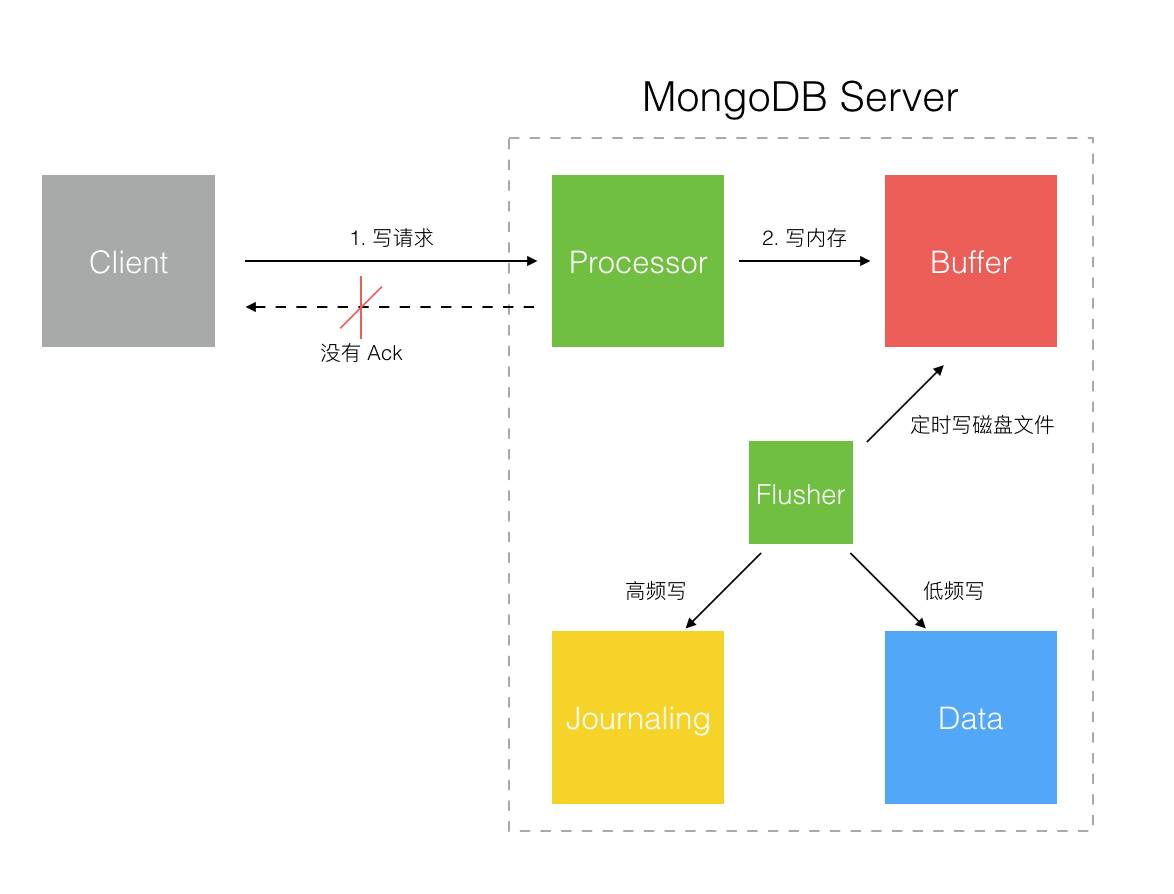
這個模式下 MongoDB 是不確認寫請求的,Client 端調用驅動寫入后若沒有網絡錯誤就認為成功,實際到底寫入成功沒有是不確定的。即使網絡沒有問題,數據到達 MongoDB 后它先保存在內存 Buffer 中,再異步寫入 Journaling 日志,這中間有 100ms(默認值) 的落盤(寫入磁盤)時間窗口。一般數據庫的設計都是先寫 Journaling 的流水日志,隨后異步再寫真正的數據文件到磁盤,這個可能就比較長了,MongoDB 是 60 秒或者 Journaling 日志達到 2G。
Write To Buffer With ACK
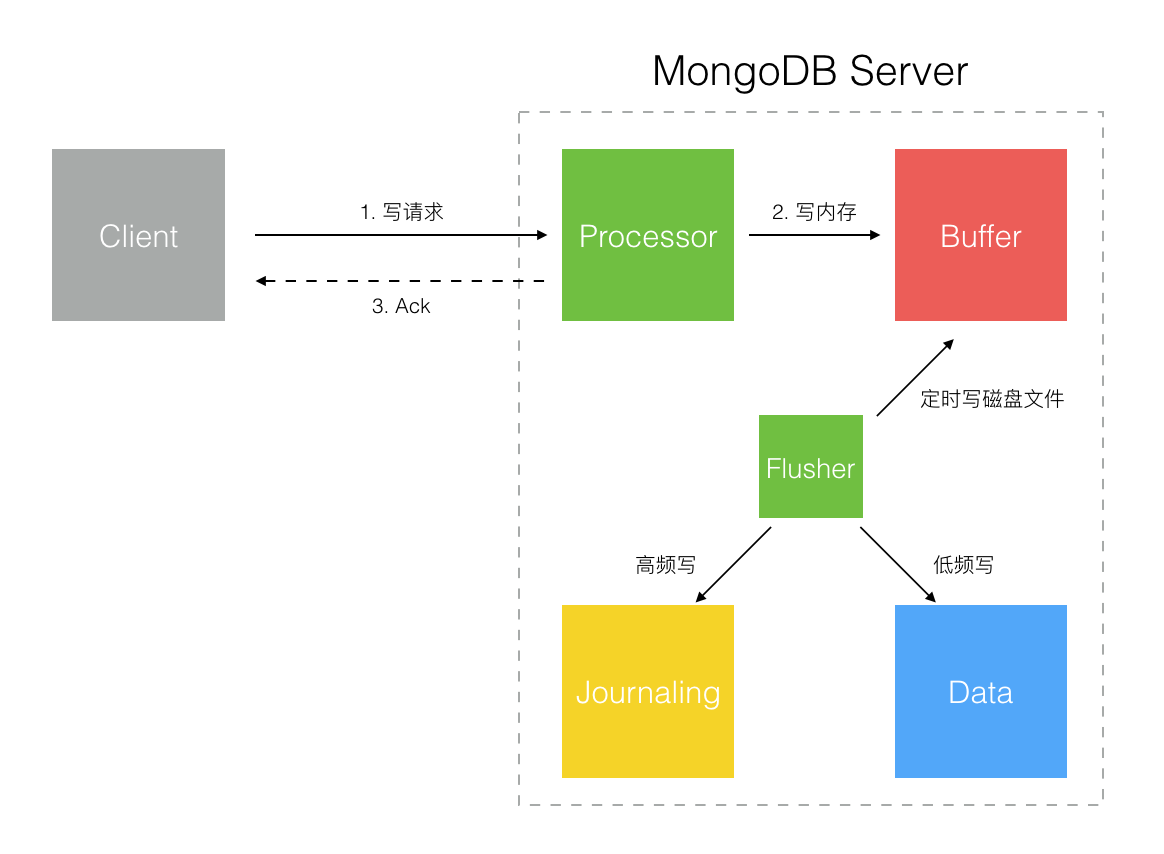
這個比上一種模式稍微好一點,MongoDB 收到寫入請求,先寫入內存 Buffer 后回發 Ack 確認。Client 端能確保 MongoDB 收到了寫入數據,但依然有短暫的 Journaling 日志落盤時差導致潛在的數據丟失可能。
Write To Journaling With ACK
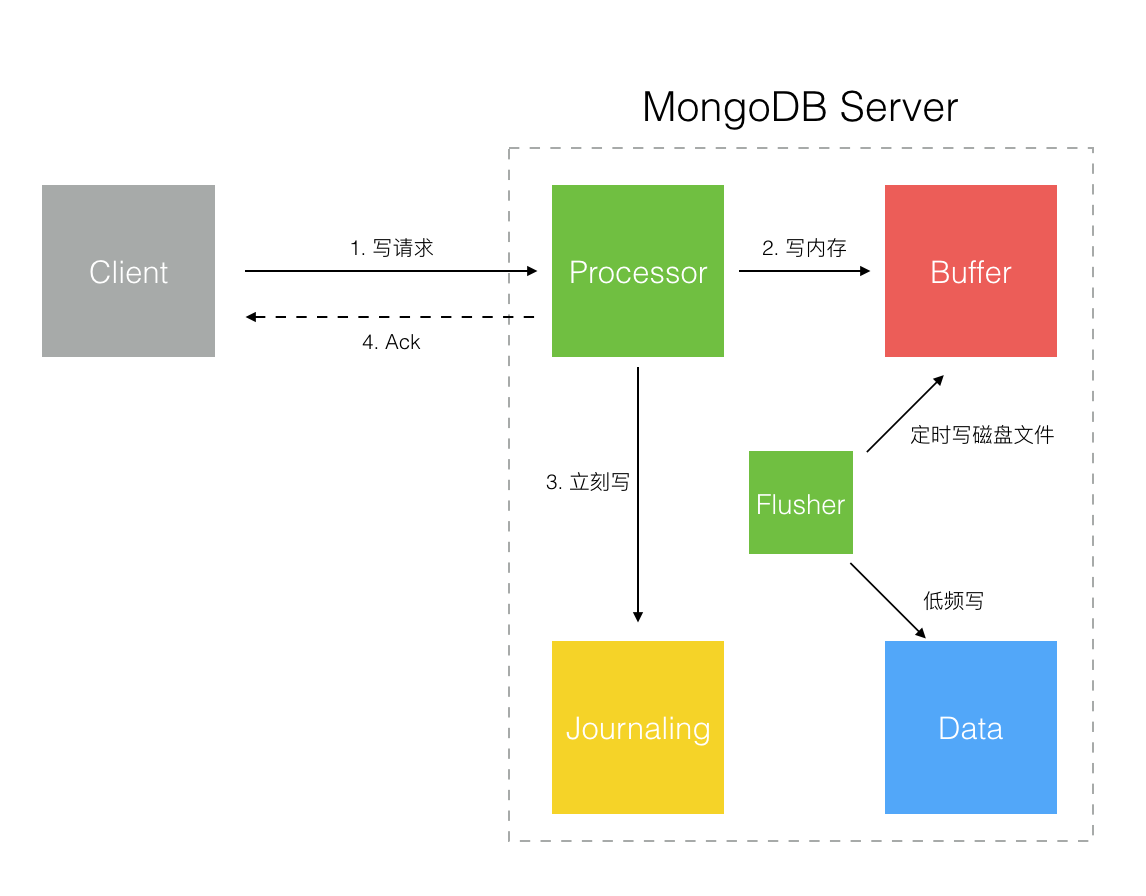
這個模式確保至少寫入 Journaling 日志后才回發 Ack 確認,Client 端能確保數據至少寫入磁盤了,安全性較高。
Write To Replica Buffer With ACK

這個模式是針對多副本集的,為了提升數據安全性,除了及時寫入磁盤也可以通過寫多個副本來提升。在這個模式下,數據至少寫入 2 個副本的內存 Buffer 中才回發 Ack 確認。雖然都在內存 Buffer 中,但兩個實例在落盤短暫的 100ms 時差中同時故障的概率很低,所以安全性有所提升。
MMAPv1 和 WiredTiger 有什么區別?
- MMAPv1 是 Mongo 在 3.0 以前的存儲引擎,WiredTiger 是 Mongo 在 3.2 及以后版本的默認存儲引擎;
- MMAPv1 只是單純地將 BSON 數據直接存儲在磁盤上,WiredTiger 則會在數據從內存存儲到磁盤前進行一次
壓縮; - MMAPv1 在 3.0 版本之前,以 database 為單位加鎖,對同一個Database的其他Collection所做的操作也會被阻塞。 而到了 3.0 版本,MMAPv1 則開始使用以 Collection 為單位的加鎖。WiredTiger 是基于
Document 級鎖機制。
MMAPv1 是如何分配記錄的?
在MongoDB中,每條數據以 Document 的形式進行存儲,并通過 Collection 來管理Document。同一個Collection中的Document會根據插入(insert)的先后順序, 連續地寫入到磁盤的同一個區域(region)上。MMAP在第一次插入時會為每個Document開辟一小塊專屬的區域,你可以管它叫一個"record"(記錄),或一個"slot"(record這個名字容易和別的東西混淆,所以后面我會管它叫slot), 其他新插入的Document則必須從這一小塊區域的結尾處開始寫入。
為了避免 update 時 Document 變大重新分配空間,創建 Document 時會預留一定的空間,稱為 padding,可以降低重新分配 Document 的幾率。
WiredTiger 是如何實現 Document 級鎖的?
在平常的使用中,大多數對數據庫的更新操作都只會對某個 Collection 中的少量 Document 進行更新。對多個Collection進行同時更新的情況已是十分稀有,對多個 Database 進行同時更新則是更為罕見了。 由此可見,加鎖粒度最小只支持到 Collection 是遠遠不夠的。相對于 MMAPv1,WiredTiger 使用的實際為 Document 級的樂觀鎖機制。
WiredTiger的樂觀鎖機制與其他樂觀鎖機制實現大同小異。WiredTiger會在更新Document前記錄住即將被更新的所有Document的當前版本號,并在進行更新前再次驗證其當前版本號。 若當前版本號沒有發生改變,則說明該Document在該原子事件中沒有被其他請求所更新,可以順利進行寫入,并修改版本號;但如果版本號發生改變,則說明該Document在更新發生之前已被其他請求所更新, 由此便觸發了一次“寫沖突”。不過,在遇到寫沖突以后,WiredTiger也會自動重試更新操作。








