ch2 利用用戶行為數據
為更好的對每個用戶服務,需要深入挖掘用戶的行為數據。用戶的行為不是隨機的,其中蘊含有模式和規律。推薦算法的任務就是在數據中尋找這些規律,提高用戶體驗。基于用戶行為數據的推薦算法是推薦系統中重要的算法,又稱為協同過濾算法。
2.1 用戶行為數據簡介
用戶行為在推薦系統中一般分為兩種:顯性反饋數據和隱形反饋數據。顯性反饋行為明確表示用戶的洗好,比如直接讓用戶對物品進行評分和分類。隱式反饋行為指不明確用戶喜好的行為,比如用戶的頁面瀏覽行為。
2.2 用戶行為分析
- 用戶活躍度和物品流行度的分布
- 用戶活躍度和物品流行度的關系
- 新用戶傾向于熱門物品,老用戶傾向于冷門物品。
給予用戶行為數據設計的推薦算法一般稱為協同過濾孫發,如基于領域的方法(Neighborhood-based)、隱語義模型(Latent factor model)、給予圖的游走算法(Random walk on graph)。基于領域的方法是最常用算法,主要包含:
- 基于用戶的協同過濾算法:給用戶推薦相似用戶喜歡的物品
- 給予物品的協同過濾算法:給用戶推薦之間喜歡物品的相似物品
2.3 實驗設計和算法評測
這里討論的是 TopN 問題
2.3.1 數據集
選擇MovieLens數據集。
2.3.2 實驗設計
將數據集分為M份,在M-1部分進行訓練,并在剩余部分進行預測。進行M次實驗,求平均值。
2.3.3 評測指標
\bigcap T(u)|}{\sum_{u \in U}|T(u)|}$$)
\bigcap T(u)|}{\sum_{u \in U}|R(u)|}$$)
|}{|I|}$$)
2.4 基于領域的方法
2.4.1 基于用戶的協同過濾算法
基于用戶的協同過濾算法是最古老的算法,也是最基礎的算法。
1.基礎算法
- 找到與目標用戶相似的用戶集合。
- 找到級和中用戶喜歡的但沒有聽說的物品。
這里的關鍵在如何計算用戶的相似度,協同過濾主要利用用戶行為的相似度來計算。給定用戶u和用戶v,N(u)定義為用戶u有過正反饋物品的集合。可用Jaccard計算u和v的相似度:
\bigcap N(v)|}{|N(u)\bigcup N(v)|}$$)
或使用余弦相似度計算:
\bigcap N(v)|}{\sqrt{|N(u) N(v)|}}$$)
得到用戶相似度后,UserCF會給用戶推薦與他最相似K個用戶喜歡的物品。使用如下公式計算用戶u對物品i的興趣:
=\sum_{v\in S(u, K) \bigcap N(i)}w_{uv}r_{vi}$$)
其中S(u, K)為與用戶u最相似的K個用戶,N(i)是物品i有過行為的用戶集合,$w_{uv}$為用戶u和用戶v之間的相似度。
2.用戶相似度的改進
如果兩個用戶都買了熱門商品,并不能表示他們之間很相似。該進的相似度如下:
 \bigcap N(v)}\frac{1}{log1+|N(i)|}}{\sqrt{|N(u)N(v)|}}$$)
2.4.2 基于物品的協同過濾算法
1.基礎算法
給用戶推薦和他們之間喜歡的物品相似的物品,但ItemCF并不計算物品內容屬性的相似度,而是通過分析用戶行為記錄來計算物品之間的相似度。
- 計算物品之間的相似度
- 根據物品相似度得到推薦列表
物品相似度定義為:
 \bigcap |N(j)|}{\sqrt{|N(i)|}}$$)
N(i)表示喜歡物品i的用戶數,$N(i) \bigcap |N(j)$表示喜歡物品i和物品j的用戶數。但是如果物品j非常熱門,則公式會造成任何物品都會和熱門物品有高的相似度,改進的公式如下:
 \bigcap |N(j)|}{\sqrt{|N(i)N(j)|}}$$)
在物品協同過濾中,兩個物品之間的相似度是因為它們被很多用戶喜歡。如果每個用戶興趣都局限在某幾個方面,因此如果某兩個物品屬于同一個用戶列表,則兩個物品屬于有限的領域;如果兩個物品同時屬于很多用戶的列表,則它們很可能屬于同一個領域,有較高的相似度。
得到物品相似度后,使用如下公式計算用戶u對物品i的興趣:
=\sum_{v \in N(u) \bigcap S(j, k)}w_{ij}r_{ui}$$)
2.用戶度對物品相似度的影響
即活躍用戶對物品相似度的貢獻小魚不活躍用戶:
 \bigcap |N(j)}\frac{1}{log1+|N(u)|}}{\sqrt{|N(i)N(j)|}}$$)
3.物品相似度歸一化
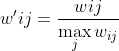
歸一化的好處在于增加推薦的準確度,還提高推薦的覆蓋率和多樣性。
2.4.3 UserCF和ItemCF的比較
UserCF給用戶推薦和他有共同愛好的物品,ItemCF給用戶推薦和他之間喜歡物品相似的物品。UserCF推薦側重于反應和用戶興趣相似的小群體的特點,而ItemCF推薦側重于維系用戶歷史興趣。
UserCF反應的是相似群體中物品熱門,ItemCF反應的是自己的興趣傳承。
2.5 隱語義模型
2.5.1 基礎算法
通過隱含特征聯系用戶興趣和物品:對物品進行分類,在分類中挑選他可能喜歡的物品。從數據本身出發,自動找到物品分類,隱語義模型本質上是類似的。
LFM通過如下公式計算用戶u對物品i的興趣:
=r_{ui}=p^T_u q_i=\sum^F_{f=1}p_{u,k}q_{i,k}$$)
其中$p_{u,k}$衡量用戶u的興趣與第k個隱含類的關系;$q_{i,k}$度量了第k個隱含類與物品i之間的關系。
LFM在評分數據上有了很好的精度,也可以在隱含反饋上進行應用。
